本周二,nvidia的股价再次超越苹果,成为全球最有价值的公司,继今年6月创下类似纪录后,再度迎来辉煌时刻。在过去两年中,凭借的强大算力,nvidia在ai时代可谓风光无限,芯片性能不断攀升,取得了巨大的市场成功。
然而,不得不指出的是,尽管gpu技术飞速发展,仍有一些短板技术正在成为英伟达发展的隐性障碍,影响着其进一步的突破。
高歌猛进的gpu
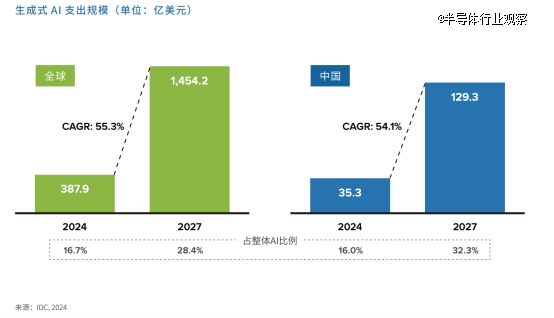
近一两年来,我们可以看到gpu的速度迭代非常快,背后很大的因素是生成式ai(大模型)的爆发式增长。idc预测到2027年,全球生成式ai市场规模将攀升至1454亿美元,中国市场的投资也将达到129亿美元,idc指出,这一发展趋势的动力源自技术迭代的加速、应用领域的拓宽,以及企业对ai创新驱动的不懈投入。
算力是生成式ai发展的物理基础,gpu是加速计算的主要工具。要实现大模型的突破,就需要大幅提高gpu的性能。gpu目前正进入一种“自我加速”的发展模式。英伟达和amd等厂商面临着巨大的市场压力,它们必须不断在硬件设计上推陈出新,力求实现每年一个小迭代、每两年一个大迭代,才能满足这些需求。即使hopper h100 gpu平台是“历史上最成功的数据中心处理器”,但黄仁勋在今年的computex主题演讲中说到,nvidia也必须继续努力。
英伟达的gpu架构从fermi到hopper再到blackwell,每次架构升级都带来性能和能效上的显著提升。从“pascal”p100 gpu一代到“blackwell”b100 gpu一代,八年间gpu的性能提升了1000多倍。
虽然过去八年性能提升了1000多倍,但是gpu的价格仅上涨了7.5倍。据了解,nvidia的新款基于blackwell的gb200 gpu系统能够以比上一代h100系统的推理速度快30倍。
由于对数据中心gpu的需求,nvidia的市值自2023年初以来增长了近十倍。2023年初,英伟达的市值为3600亿美元。不到两年后,其市值已超过3.4万亿美元。
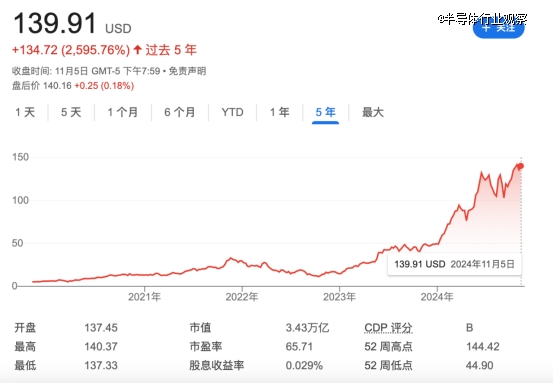
nvidia市值超越苹果成为全球最有价值的公司
gpu规模的发展速度之快是前所未有的,就拿amd来说,在amd 2024年第三季度财报电话会议上,amd ceo lisa su指出,其gpu销量已接近cpu销量,这点与amd涉足ai市场大有关系。amd的ai gpu业务才刚开始一年,营收就已经快达到cpu业务规模。
在财报会上,lisa su还表示:“仅在数据中心,我们预计ai加速器市场规模将以每年60%以上的速度增长,到2028年将达到5000亿美元。这大致相当于2023年整个半导体行业的年销售额。”amd将2024年gpu销售额预测从45亿美元上调至50亿美元以上。
然而,gpu这样的快速发展也带来了新问题。随着gpu性能的不断提升,背后支持它们的基础设施——尤其是互联技术和技术——却显得相对滞后。
跟不上的互联技术
如今,大型语言模型(llms)如chatgpt、chinchilla和palm,以及推荐系统如dlrm和dhen,都在成千上万的gpu集群上进行训练。训练过程包括频繁的计算和通信阶段,互联技术就显得尤为关键。
传统的互联技术如pcie(外围组件互联)接口的带宽已难以支撑日益增大的数据传输需求,也早已经跟不上gpu的速度,pcie标准虽然逐步演进,但它的传输带宽与gpu处理能力之间的差距越来越大。特别是在多卡并行计算的场景中,pcie显得捉襟见肘,限制了gpu的*性能释放。尽管目前许多大公司尝试采用标准pcie交换机,并通过基于pcie的结构扩展到更多加速器,但这只是权宜之计。
为了应对这一瓶颈,英伟达开发了自家的高速互联技术——nvlink和infiniband。nvlink技术可用于gpu之间的高速点对点互连,提供高带宽和低延迟的数据传输,并通过peer to peer技术完成gpu显存之间的直接数据交换,进一步降低数据传输的复杂性。这对于分布式环境下运行的复杂ai模型尤为重要。更快的纵向互联有助于服务器集群内每个gpu性能的充分释放,从而提升整体计算性能。
至于infiniband技术,是一种网络连接技术。英伟达于2019年收购了mellanox technologies,mellanox是全球*的infiniband技术提供商之一。收购后,英伟达继续推进infiniband技术的创新,并在其加速计算平台中深度集成了infiniband网络。虽然以太网(ethernet)在很多应用中是主流的网络连接技术,但在高性能计算(hpc)和ai训练等场景中,infiniband相较于以太网,具有显著优势:它提供更高的带宽、更低的延迟,且原生支持远程直接内存访问(rdma),使得数据传输更加高效。
而amd则推出了自己的infinity fabric互联技术,专为数据中心优化,旨在提升数据传输速度和降低延迟。不过infinity fabric自然也是比不过nvlink的,不然amd也不会发起ualink联盟。
nvlink和infiniband技术虽然具有明显优势,但它们都是英伟达的专有技术。随着行业对互联技术需求的不断增长,一方面希望避免英伟达在技术上的垄断,另一方面也面临着互联技术瓶颈的挑战。因此,许多企业开始对标英伟达的互联技术,尝试开发替代方案。
去年7月19日,超级以太网联盟(uec)成立,来对标infiniband。创始成员包括amd、arista、broadcom、思科、eviden(atos旗下企业)、hpe、英特尔、meta和微软。目前超级以太网联盟已经吸引了67家公司的加入。其中不乏许多初创公司,联盟的成立将使这些初创公司从该联盟的举措中受益匪浅,uec将成为初创公司在优化tco的同时驾驭复杂的ai和hpc网络格局的关键。
据tomshardware的报道,ualink最有可能经常以较小的规模使用,大约8个服务器的pod通过ualink相互通信,进一步的升级由超级以太网处理。联盟成员将在今年获得该规范的访问权限,并于2025年*季度开始进行全面审查。
无论是nvlink、fabric还是ualink,这一系列举措反映出现有互联技术跟不上加速器发展速度的普遍问题,行业迫切需要新的k8体育的解决方案来支持更强劲的算力需求。
存储更吃力
与互联技术的滞后相比,存储技术的进步似乎显得更加吃力。在ai、机器学习和大数据的推动下,数据量呈现出指数级的增长,存储技术必须紧随其后,才能确保数据处理的效率和速度。对于当前的内存行业来说,高带宽内存(hbm)已经成为焦点,尤其是在大模型训练所需的gpu芯片中,hbm几乎已经成为标配。
gpu依赖于高带宽内存(hbm)来满足高速数据交换的需求。与cpu相比,gpu需要更加频繁的内存访问,且数据的访问模式具有很高的并行性。这要求存储系统必须能够在毫秒级的延迟内提供极高的数据带宽。
2013年,sk海力士推出了*hbm芯片,直到大模型的崛起,hbm才真正迎来了应用的黄金时机。近年来,sk海力士加速推进hbm技术的更新迭代。今年9月,sk海力士成功批量生产了全球*12层hbm3e产品,并计划于2025年初推出首批16层hbm3e芯片样品。原本预计在2026年量产的hbm4,sk海力士已将时间表提前,预计将在2025年下半年交付12层hbm4芯片。
尽管如此,黄仁勋仍在敦促sk海力士加快hbm4的供应,初步要求提前6个月交付。虽然hbm的需求火爆,存储厂商依然面临着生产能力、技术瓶颈和成本等多重挑战。
存储技术的滞后给高性能计算带来了多重挑战:
计算能力浪费:gpu的强大计算能力无法得到充分利用,存储瓶颈导致大量的gpu计算资源处于空闲状态,无法高效地执行任务。这种不匹配导致了系统性能的低效发挥,增加了计算时间和能源消耗。
ai训练效率下降:在深度学习训练过程中,大量的数据需要频繁地在gpu与存储之间交换。存储的低速和高延迟直接导致ai训练过程中的数据加载时间过长,从而延长了模型训练的周期。这对于需要快速迭代的ai项目来说,尤其是商业应用中,可能会造成较大的成本压力。
大规模数据处理的障碍:随着大数据的兴起,许多ai应用需要处理海量数据。当前存储技术未能有效支持大规模数据的快速处理和存储,特别是在多节点分布式计算的场景中,存储瓶颈往往成为数据流动的*障碍。
为了解决存储跟不上gpu发展的瓶颈,业界已经提出了一些潜在的k8体育的解决方案:例如存算一体以及cxl这样的智能存储架构。
随着处理器在内存(pim)技术的兴起,计算和存储有可能进行更紧密的集成。pim技术允许计算任务直接在存储设备上进行处理,避免了数据在计算和存储之间的传输瓶颈。此类技术有望大幅提升存储系统的性能,并有效支持gpu等计算芯片的高速数据访问需求。
智能存储架构:采用更智能的存储架构,如cxl(compute express link)和nvme协议,可以实现更高效的存储扩展和更低延迟的数据访问。cxl提供了计算和存储之间的高速互联,使得gpu能够更快速地访问存储数据,解决传统存储架构中存在的带宽瓶颈问题。
存储技术滞后于计算芯片发展的现象,显然已经成为现代计算系统中的瓶颈。尽管存储技术已经取得了一些进展,但与gpu等计算芯片的快速发展相比,仍存在较大的差距。
总结
在当今快速演变的技术生态系统中,多技术协同升级已成为推动新兴技术发展的核心动力。要实现算力的持续增长,gpu、互联、存储等技术必须协调发展。虽然gpu技术已取得了显著进步,但没有更高效的互联技术和更快的存储技术支撑,算力的潜力将无法完全释放。
对于英伟达等科技巨头而言,如何继续推动gpu与其他关键技术的协同进化,解决存储、互联的瓶颈,将是未来几年中的主要挑战。